리뷰해볼 논문은 MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis으로 연구실 세미나를 위해서 준비했던 논문이다. HIFI-GAN이나 SoundStream같은 뉴럴 코덱쪽에서 뛰어난 성능을 보이는 모델들에서 사용된 뉴럴코덱의 기본이 되는 논문이다. 코드도 공개되어 있으니 함께 보시면 코드 공부하기도 좋고 기초 쌓기도 좋은 논문이었던 거 같다. 논문 리뷰는 내가 세미나를 발표했던 순으로 진행해보도록 하겠다.
Introduction
raw audio를 모델링하는 것은 어려운 task라고 말할 수 있다. 여러 가지 이유가 있겠지만 크게 2가지 정도를 생각해 볼 수 있다. 첫 번째는 data의 높은 temporal resolution이다. 쉽게 말하자면 CD Quality가 44.1khz로 샘플링되는데, 이는 초당 44100개의 데이터가 존재하는 것을 의미한다. 두 번째는 short-term과 long-term depedenciey이다. 오디오는 다양한 timescale의 dependency를 갖고 있으며 이를 포착해서 분석하는 것은 쉽지 않은 일이다.
따라서 대부분은 입력 데이터를 lower-resolution representation으로 모 델리애서 문제를 단순화해서 해결하려고 한다. Speech의 경우에는 aligned linguistic feaures(시간과 feature가 정렬된 데이터)나 mel-spectrograms들이 일반적으로 intermediate representations(중간 표현)으로 사용된다.
Audio medelling은 크게 2가지 단계로 나눠서 생각할 수 있다.
1) 첫 번째는 입력을 중간표현으로 mapping 하는 것.
2) 중간표현을 다시 audio로 변환하는 것.
본 논문에서는 제목에서부터 알 수 있듯이 mel-spectrogram을 중간 표현으로 사용하였다.
mel-spectrogram을 audio로 inversion하는 방법은 크게 3가지 영역으로 연구가 진행되어 왔다.
Pure signal processing techniques
딥러닝 기법을 사용하지 않은 순수한 신호처리 방법이다.
1) Griffin-Lim (Griffin & Lim, 1984) : STFT magnitude를 이용해서 STFT phase를 추정해서 원 신호를 복원해내는 방법으로 robotic한 artifacts가 많이 발생함
2) WORLD (MORISE et al., 2016) vocoder : mel-spectrogram-like한 feature (F0, envelope, aperiodicty)를 추출해서 이를 통해서 다시 원 신호를 복원해내는 방법
전통적인 신호처리 기법을 사용한 방법들은 noticeable artifacts가 많이 발생한다는 단점이 있다.
Autoregressive neural-networks-based models
–WaveNet (van Den Oord et al., 2016) is a fully-convolution autoregressive sequence model that produces highly realistic speech samples conditioned on linguistic features that are temporally aligned with the raw audio.
–SampleRNN (Mehri et al., 2016) is an alternative architecture to perform unconditional waveform generation which explicitly models raw audio at different temporal resolutions using multi-scale recurrent neural networks.
–WaveRNN (Kalchbrenner et al., 2018) is a faster auto-regressive model based on a simple, single-layer recurrent neural network.
딥러닝을 사용한 방법들로 조건부 확률을 딥러닝으로 모델링해서 오디오를 모델링하는 방법들이다. 입력 신호를 프레임 단위로 잘라서 각 시점의 프레임을 통해서 다음 시점의 출력을 예측한다. 이러한 모델들은 pure signal processing 방법들보다 고품질의 신호를 합성해낼 수 있었다. 하지만 순차적으로 audio sample들을 생성해야하는 한계로 인해서 real-time application에는 적합하지 않다는 단점이 있다.
Non autoregressive neural-networks-based models
–Parallel Wavenet (Oord et al., 2017) and Clarinet (Ping et al., 2018) distill a trained auto-regressive decoder into a flow-based convolutional student model.
–WaveGlow (Prenger et al., 2019) is a flow-based generative model based on GLOW (Kingma & Dhariwal, 2018).
Autoregressive 모델들의 한계인 느린 inference 속도를 해결하기 위해 나온 방법들이다. sample을 병렬적으로 생성해내서 GPU를 충분하게 활용한다. wavenet을 teacher model로 사용해서 knowledge distilation을 이용해서 모델을 학습하는 방법과 glow라는 모델을 기반으로 하는 waveglow가 존재한다. inference속도는 빠른 반면, 모델들의 큰 사이즈로 인한 메모리 제약으로 실제 application에 적용하기는 어렵다.
GANs for audio
생성모델하면 뺄 수 없는 GAN은 비전 분야에서는 충분한 성공을 거두었음에도 audio에서는 큰 진전이 없었다. 따라서 다양한 연구가 진행되었지만 이전까지의 결과는 adverarial loss 단독으로는 고품질의 waveform 생성이 충분치 않다는 한계를 보여주었다.
Main contributions
1) MelGAN은 저자들이 아는한 추가적인 distilation이나 perceptual loss function없이 audio generation을 성공적으로 train한 GAN 모델
2) MelGAN이 어떤 synthesis framework의 autoregressive model 기반의 decoder를 쉽게 대체할 수 있다는 것을 실험으로 보여주었다.
3) MelGAN은 다른 mel-spectrogram inversion model들보다 뛰어난 속도를 보여주었다.
Method

MelGAN의 구조는 일반적인 GAN 모델들과 동일하게 fake sample을 생성하는 generator와 real sample과 fake sample을 판별해내는 discriminator로 이루어졌다.
Generator (Architecture)
- MelGAN은 CNN으로 이루어진 fully convonlution network이다.
- 입력은 mel-spectrogram s(256배 down sampling), 출력은 raw waveform x
- 출력 신호의 resolution을 맞추어주기 위해서 upsampling layer로 구성되어있으며 transpose convolution을 사용함.
- transpose convolution의 kernel size는 stride의 두 배로 이루어짐.
- MelGAN은 다른 일반적인 GAN과는 다르게 global noise vector를 입력에 사용하지 않는다. 이는 mel-spectrogram s가 원래 입력 신호의 정보를 강하게 가지고 있기 때문에 어떠한 noise가 복원 결과에 크게 영향을 주지 않음을 의미함. 이러한 강력한 조건으로 인한 생성 결과는 이전의 다른 논문들의 실험과 일관성 있다고 한다.
Generator (Residual stack)
위에서 제시된 generator 구조를 보면 upsampling layer뒤에 residual stack이 위치해있는 것을 볼 수 있다. 그러면 residual stack이 무슨 역할을 하는 지 알아보도록 하겠다. 처음 intro에서 언급했듯이 audio는 short-term과 long-term depedency를 가지고 있다. 이는 신호의 특성을 파악하기 위해서는 신호를 short하게 보는것 뿐만 아니라 long하게 볼 필요도 있다는 것을 의미한다. residual stack은 이러한 long-term dependency를 보다 효율적으로 파악하게 해준다.
Residual stack은 dilated convolution과 skip connection을 통해서 구현되어있다. 위의 이미지는 dilated conovlution을 쉽게 설명하기 위한 예시이다. 원리는 간단하다. 위의 network의 kernel size는 2, stride는 1, dilation은 1, 2, 4, 8로 설정되어있다. 첫 번째 hidden layer의 노드는 이전 출력에서의 convolution 계산(2개의 샘플)을 통해서 2개의 timesteps을 가지고 있다. 그 다음 hidden layer를 살펴보자. 이때는 이전 layer보다 dilation factor가 2배 증가한 2이고 마찬가지로 kernel의 크기가 2인 필터를 통해서 나온 결과는 마찬가지로 첫 번째 hidden layer의 2개의 노드에 대한 결과이다. 그렇지만 input sample의 관점에서 보면 2개의 time steps의 정보를 가진 2개의 노드를 convolution을 한 것이기 때문에 2번째 hidden layer는 4개의 timesteps에 대한 정보를 갖고 있게 된다. 이런식으로 dilation을 kernel size의 지수 형태로 증가시킨다면 효율적으로 time steps을 증가시킬 수 있다.

본 논문에서는 kernel size 3으로 설정하고 dilation factor는 1, 3, 9로 총 27개의 time steps을 갖도록 구현하였으며, 활성화 함수로는 leaky-relu를 사용한다.
Generator (Checkerboard artifacts)
https://distill.pub/2016/deconv-checkerboard/
Deconvolution and Checkerboard Artifacts
When we look very closely at images generated by neural networks, we often see a strange checkerboard pattern of artifacts.
distill.pub
checkerboard artifact는 transpose convolution을 이용했을 때 생기는 문제점이다. kernel size와 stride를 적절하게 선택하지 않으면 발생하는 문제로 위의 링크에서 해당 문제에 대해서 더 자세하게 살펴볼 수 있다.
MelGAN에서 이 문제를 해결하기 위한 방법에 대해서만 이야기해보면
1) kernel-size를 stride의 배수로 설정하였다.
2) dilation factor를 kernel-size의 지수형태로 증가시켰다.
이렇게 설정하면 왜 checkboard를 피할 수 있는지는 링크에서 자세하게 살펴볼 수 있다.
Generator (Normalization)
1) 처음에 저자들이 적용한 normalzation 기법은 이미지 분야에서 주로 사용되는 instance normalization으로 해당 방법은 중요한 pitch information들이 소실되어 audio가 metallic하게 들리게 만들었다고 함.
2) 다음으로 적용한 기법은 spectral normalization으로 마찬가지로 poor한 결과를 얻었다고 한다.
최종적으로 저자들이 적용한 기법은 weight normalization이다. 해당 기법이 잘된 이유는 discriminator의 표현력을 제한한다거나 activation을 normalize하지 않아서 결과가 좋았다고 말하고 있다. weight normalization은 weight vector를 방향과 크기를 나타내는 파라미터로 다시 reparametrize를 해서 각각을 업데이트하는 방식으로 weight를 업데이트한다. 이렇게 진행하면 각각의 요소가 서로에게 영향을 주지않아서 더 안정적인 업데이트가 가능하다고 한다.
Discriminator (Multi-Scale Architecture)

저자들은 신호의 다양한 주파수에 대해서 학습시키기 위해서 단일 discriminator를 사용하는 것이 아닌 동일한 구조의 입력 scale이 다른 multi-scale discriminator를 사용했다. 총 3개의 discriminator를 사용했으며, D1은 원본의 입력, D2는 avg pooling을 통한 2배 downsampling, D3는 avg pooling을 통한 4배 downsampling된 신호를 입력으로 사용하였다.
이런 multi-scale architecture를 통해 down sampling된 신호를 입력으로 받는 D2와 D3는 고주파에 대해서 학습하지 못하기 때문에 저절로 저주파에 집중하게 되기 때문에 다양한 범위의 주파수를 학습할 수 있었다고 한다.
Discriminator (Window-based objective)

이미지를 patch 단위로 잘라서 real인지 fake인지 판단하는 patchgan의 아이디어를 적용한 방법이다. 이를 audio로 적용해서 생각해보면 input signal을 큰 커널 사이즈를 갖는 필터로 overlap해서, 즉 audio를 청크단위로 나누어서 feature를 추출한다고 생각할 수 있다. 청크 단위로 나누어서 확인하기 때문에 더 고주파에 대한 feature를 포착할 수 있다. 그치만 이러한 방법은 큰 커널 사이즈를 여러개 overlap하기 때문에 많은 파라미터 수를 요구하게 된다. 이러한 단점을 group convolution을 통해서 해결하였다. 마찬가지로 weight normalization을 적용하였다.
patchgan에 대해서는 더 자세하게 알고싶으면 image translation 논문인 pix2pix를 읽어보길 추천한다.
Training objective
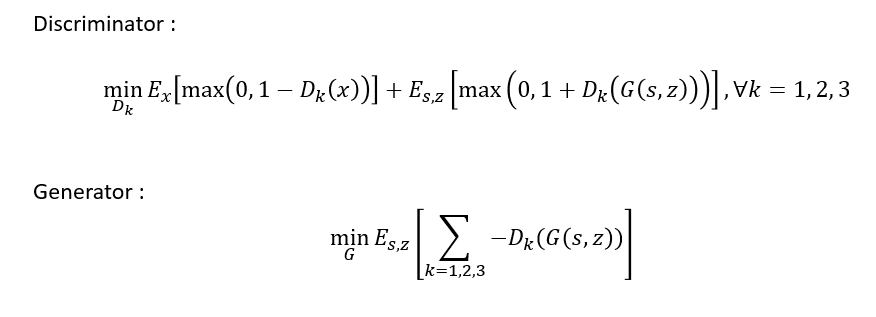
- x : raw waveform
- s : conditioning information(=mel-spectrogram)
- z : gaussian noise vector
GAN을 학습시키기 위해서 GAN의 hinge loss version을 사용하였다. 아마 본 논문에서는 Discriminator의 expectation 부분이 max가 아닌 min일텐데 이는 오타로 보인다. multi-scale 구조를 사용하기 때문에 k=1,2,3에 대한 discriminator를 학습한다. hinge loss는 data sample에 대해서 loss가 0보다 작으면 해당 sample에 대해서는 update가 이루어지지 않는다. generator는 discriminator의 오른쪽 term과 반대로 학습이 되게된다.

Generator의 학습에 feature matching loss가 적용된다. real과 fake에 대해서 discriminator feature map사이의 L1 distance를 최소화 하도록 학습한다.
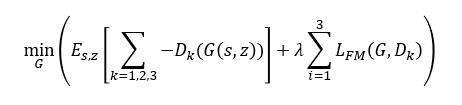
Experiments
Ablation study

- LJ speech dataset으로 400k iteration 학습
- dilated convolution과 weight normalization을 사용하지 않으면 high frequency artifacts를 유발함.
- single discriminator를 사용하면 metallic한 audio 생성.
- spectral normalization을 사용하거나 window-based discriminator를 사용하지 않으면 sharp한 high frequency patterns을 학습하기 어려웠으며 그 결과 noisy한 sound 생성.
- 추가적인 L1 loss는 오히려 성능이 저하됨.
Benchmarking competing models

당시 다른 sota 모델에 비해 성능이 떨어지나 저자들은 inference 속도와 parameter를 고려하면 충분히 경쟁력있다라고 주장함.
Generalization to unseen speakers

dataset에 포함되지 않은 화자에 대해서도 일반화가 가능함. 이는 melgan이 화자에 의존적이지 않고 mel-spectrogram으로부터 raw waveform을 mapping할 수 있음을 의미한다.
End-to-end speech synthesis

마찬가지로 inference속도와 parameter를 고려하면 경쟁력있다.
이밖에 music translation 모델과 vq-vae의 decoder(wavenet기반)를 melgan으로 교체하여도 잘 동작하며 들을만한것을 보여주며 쉽게 교체가 됨을 보여주었다.


